Abstract
Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as “hallucinations”'. Recent studies have demonstrated that LLMs' internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that---contrary to prior claims---truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the different types of errors the model is likely to make different types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs' internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model's internal perspective, which can guide future research on enhancing error analysis and mitigation.
Key Contributions
- Better Error Detection: We show that truthfulness information is concentrated in specific answer tokens, and by training probing classifiers on these tokens, we significantly improve the ability to detect errors.
- Generalization Challenges: While our method improves error detection within datasets, we find that probing classifiers do not generalize across different tasks. Our results indicate that LLMs encode multiple, distinct notions of truth.
- Error Type Prediction: The internal representations can also be used to predict the type of error, enabling the development of targeted error mitigation strategies.
- Behavior vs. Knowledge Discrepancy: We uncover a striking contradiction between LLMs' internal knowledge and external outputs—they may encode the correct answer internally but still generate an incorrect one.
What are hallucinations? A different perspective
- The term “hallucinations'” is widely used. Yet, no consensus exists on defining hallucinations: Venkit et al. identified 31 distinct frameworks for conceptualizing hallucinations!
- Significant research efforts aim to define and taxonomize hallucinations, distinguishing them from other error types. These categorizations, however, adopt a human-centric view. They focus on the subjective interpretations of LLM hallucinations, which does not necessarily reflect how these errors are encoded within the models themselves.
- This gap limits our ability to address the root causes of hallucinations, or to reason about their nature.
- For example, it is unclear whether conclusions about hallucinations defined in one framework can be applied to another framework.
- Instead, we adopt a broad interpretation of hallucinations. Here, we define hallucinations as any type of error generated by an LLM, including factual inaccuracies, biases, failures in common-sense reasoning, and others.
- This way, we cover a broad array of LLM limitations and derive general conclusions.
Methodology
Tools & Techniques
- Probing classifiers for error detection.
- Probing on the exact answer token for truthfulness detection.
- Experiments across a wide range of datasets (10) for diverse task and limitation evaluation.
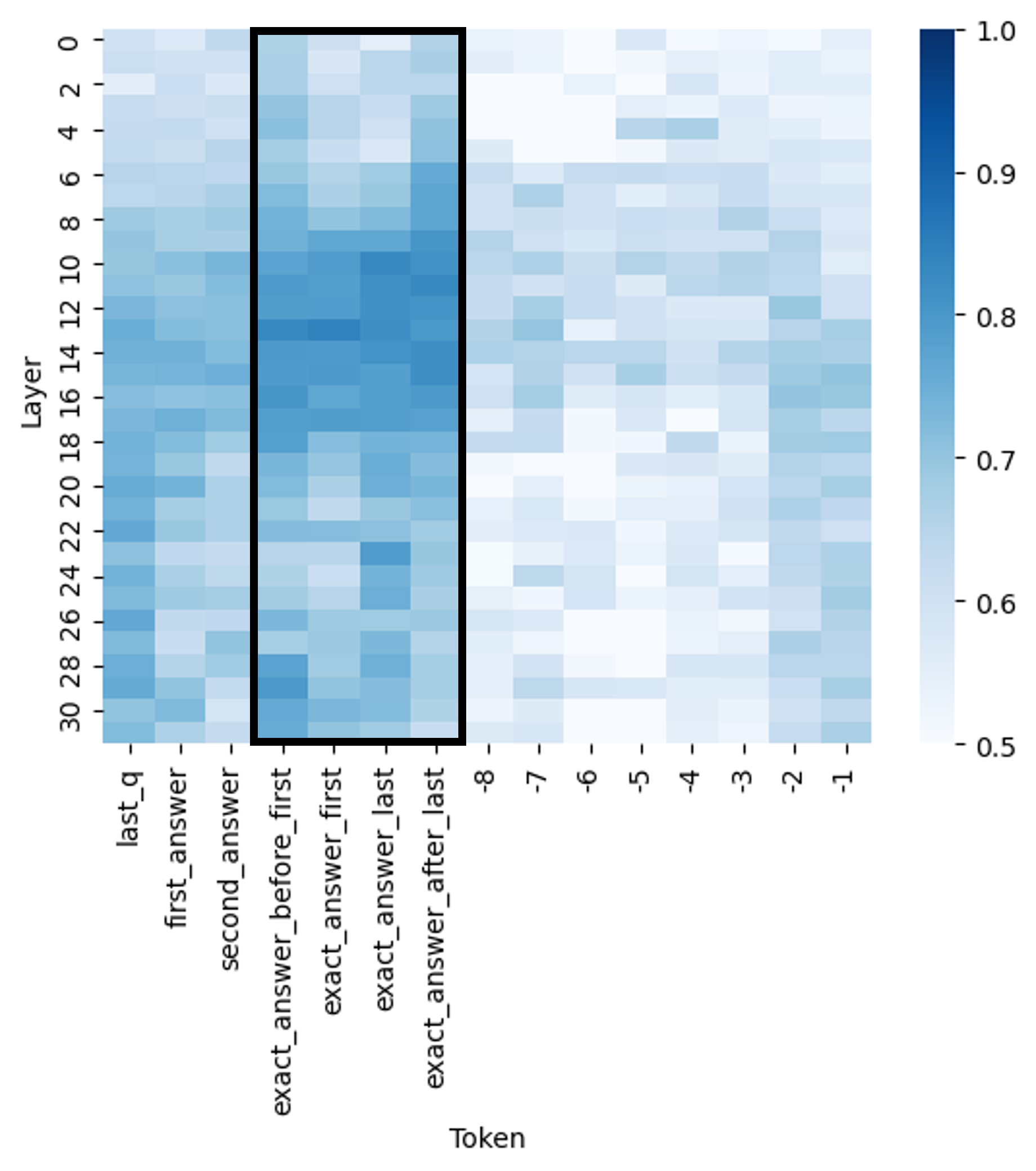
We conducted experiments across multiple datasets such as TriviaQA, HotpotQA, and MNLI to train classifiers on the internal representations of models (Mistral-7B and Llama3-8b, both pretrained and instruct). By probing the exact answer tokens within LLM outputs, we discovered stronger signals of truthfulness in the exact answer token, enabling better detection of hallucinations.

Results
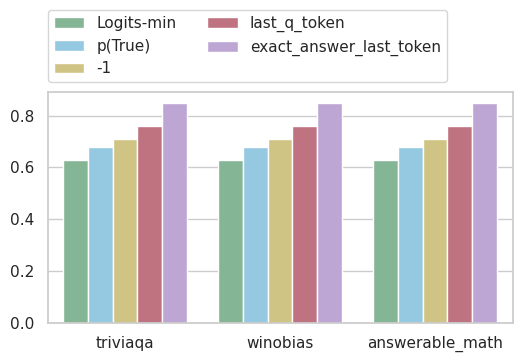
Better Error Detection
Using a probing classifier trained to predict errors from the representations of the exact answer tokens significantly improves error detection. (measured metric is AUC)
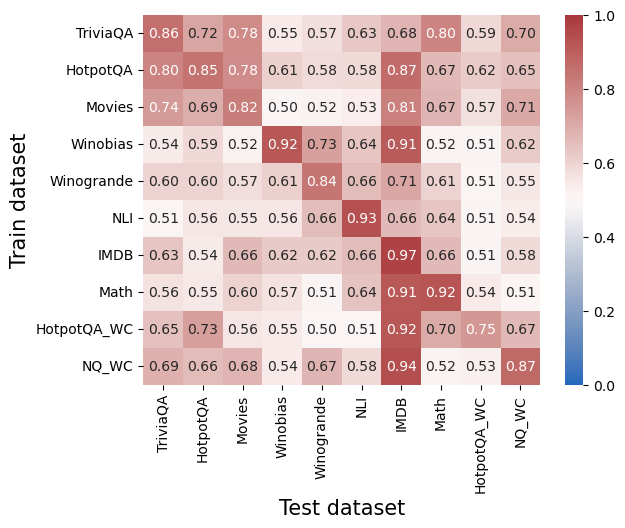
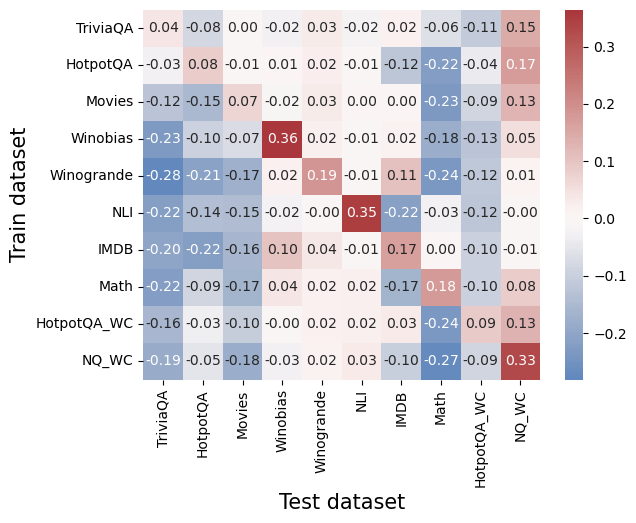
Generalization Challenges
On the left – raw generalization scores (AUC). On the right – after reducing a simple baseline of error detection using logits.
Meaning – a lot of the generalization we saw on the right can be attributed to things that the model also exposes in the output! There’s no universal internal truthfulness encoding like we might have hoped.
![]() Caution needed when applying a trained error detector across different settings.
Caution needed when applying a trained error detector across different settings.
![]() There’s more to investigate: can we map the different types of truthfulness that LLMs encode?
There’s more to investigate: can we map the different types of truthfulness that LLMs encode?
Error Type Prediction
Intuitively, not all error are the same, here are some examples for different types of errors: 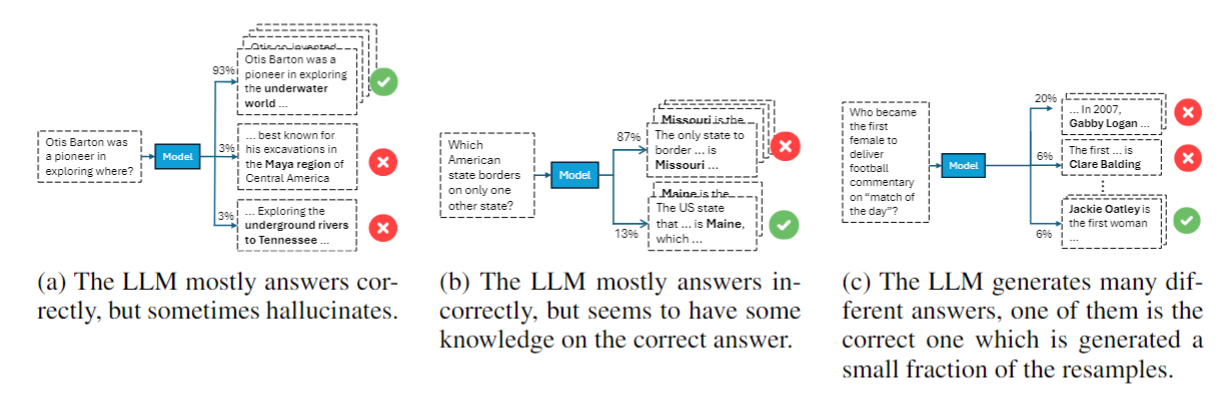
We find that the internal representations of LLMs can also be used to predict the type of error the LLM might make.
![]() Using the error type prediction model, practitioners can deploy customized mitigation strategies depending on the specific types of errors a model is likely to produce.
Using the error type prediction model, practitioners can deploy customized mitigation strategies depending on the specific types of errors a model is likely to produce.
Behavior vs. Knowledge Discrepancy
To test how aligned the model’s outputs with its internal representations, we:
- Resample 30 answers per question.
- Return the answer that the probe error detector preferred.
- Compute accuracy on the resulting outputs.
Intuitively, if there’s alignment, we should see that the accuracy is more-or-less the same as with other standard decoding methods, e.g., greedy decoding.
But this is not the case:
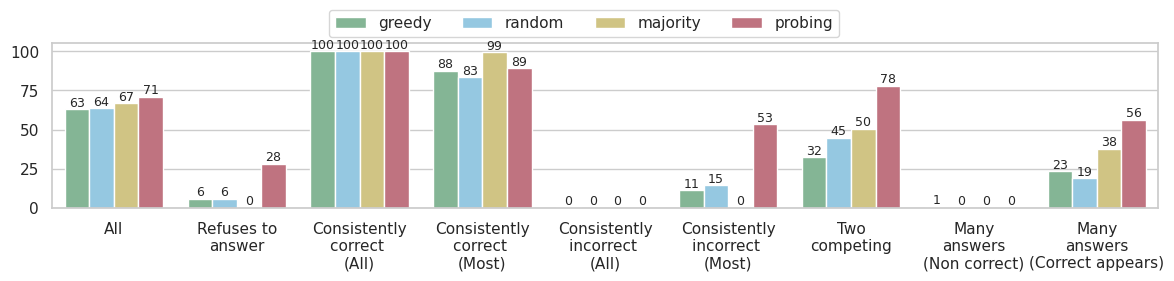
On the left – you see that overall – using the probe slightly improves the accuracy on the TriviaQA dataset.
However, if we break it down by error types – we see that the probe achieves a significant improvement for specific error types. This error types are cases where the LLM did not show any preference to the correct answer in its predictions, e.g., in “Consistently incorrect (Most)”, the model almost always predicts a specific wrong answer, while a very small fraction of the time it predicts the correct answer. Still – the probe is able to choose the correct answer, indicating that the internal representations encode information which allows it to do it.
This hints that the LLM knows the right answer, but something causing it to generate the incorrect one.
![]() Based on this insight, can we develop a method that aligns the internal representations with the LLM's behavior, making it generate more truthful things?
Based on this insight, can we develop a method that aligns the internal representations with the LLM's behavior, making it generate more truthful things?
How to cite
bibliography
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, Yonatan Belinkov, “LLMs Know More Than They Show – On the Intrinsic Representation of LLM Hallucinations”.
bibtex
@inproceedings{
orgad2025llms,
title={{LLM}s Know More Than They Show: On the Intrinsic Representation of {LLM} Hallucinations},
author={Hadas Orgad and Michael Toker and Zorik Gekhman and Roi Reichart and Idan Szpektor and Hadas Kotek and Yonatan Belinkov},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=KRnsX5Em3W}
}